几十年来,计算机CPU芯片一直按照摩尔定律飞速发展,每隔十八个月,单位芯片面积上的晶体管数量就增加一倍,性能提高一倍。由于物理极限的限制,单纯依靠制造工艺的提升已经无法满足计算需求,X86传统计算平台陷入了技术发展的瓶颈。
几十年来,计算机CPU芯片一直按照摩尔定律飞速发展,每隔十八个月,单位芯片面积上的晶体管数量就增加一倍,性能提高一倍。由于物理极限的限制,单纯依靠制造工艺的提升已经无法满足计算需求,X86传统计算平台陷入了技术发展的瓶颈。内存延时长、频率低导致缓存面积越来越大,逻辑控制越来越复杂。缓存消耗了70%以上的芯片面积,同时也消耗了70%以上的电能,真正有效的运算部件面积比重很小。芯片上的晶体管密度越来越大,使得单位面积上功耗持续增加,散热问题日益严重。
由于CPU的性能提升并不是无止境的,这也就催生出计算技术向多样化发展,而不仅仅依赖于传统的计算平台。当计算技术进一步细化,GPU作为一种独立的计算单元,以其优异的运算性能脱颖而出,为计算技术的革新带来了一种新的思路。
GPU计算是指利用图形卡来进行一般意义上的计算,而不是传统意义上的图形绘制。时至今日,GPU已发展成为一种高度并行化、多线程、多核的处理器,具有杰出的计算功率和极高的存储器带宽,如图所示。
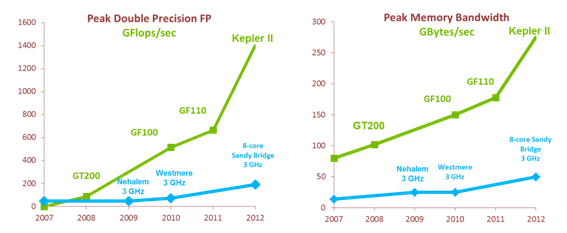
图:CPU和GPU的每秒浮点运算次数和存储器带宽
这种新技术并非突破了冯•诺依曼,而是参考CPU中传统的ALU单元,将众多的ACL单元集成到一颗芯片内部,形成ALU运算单元阵列,简化逻辑控制结构,从而满足计算密集型程序的运行,成为一个独立的计算加速单元。
CPU和GPU之间浮点功能之所以存在这样的差异,原因就在于GPU专为计算密集型、高度并行化的计算而设计,上图显示的正是这种情况,因而,GPU的设计能使更多晶体管用于数据处理,而非数据缓存和流控制,如图所示。
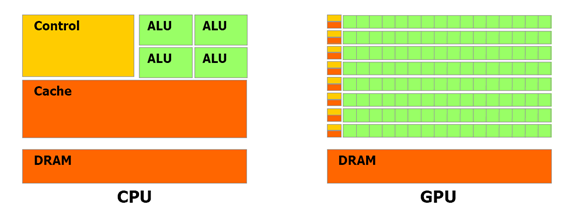
图:GPU中的更多晶体管用于数据处理
GPU计算得到了业界的广泛支持,NVIDIA、AMD、INTEL等都对芯片市场的微妙变化和GPU计算的技术发展前景都极为关注,并展开了激烈的技术竞赛。
作为异构计算领域坚定的支持者和践行者,曙光公司从国内第一套异构集群开始到HC2000异构计算方案的推出,一直在积极推进国内HPC领域的异构计算加速技术。
GPU计算方案配置选择,主要考虑以下因素:
1. 计算比例,通常应用程序的执行需要GPU与CPU协同完成,可根据GPU计算部分所占比重,配置节点GPU卡密度;
2. 计算规模,根据不同应用数据规模及计算类型,可以选择单机单GPU卡、单机多GPU卡和GPU集群应用模式;
3. 数据通信,在GPU集群模式下,可根据应用程序对集群通信带宽及延迟的需求,选择高速Infiniband网络或万兆网络;
4. 存储系统:单节点应用模式下一般数据量比较小,对存储系统性能要求不高,一般采用本地存储;集群环境下,应用数据量比较大,一般配置大容量、统一、高速的并行文件系统,另外对一些特殊应用,如石油、天然气应用,可以在每个GPU计算节点内部配置SSD硬盘,作为分级存储使用,加速节点内部数据交换;
5. 管理调度,合理选择GPU集群的作业调度和监控系统,可以提升集群的使用效率,降低维护成本。
















